TiDB在知乎万亿量级业务数据下的实践和挑战
非原创。本文根据孙晓光老师在 TiDB TechDay 2019 北京站上的演讲整理。
业务场景
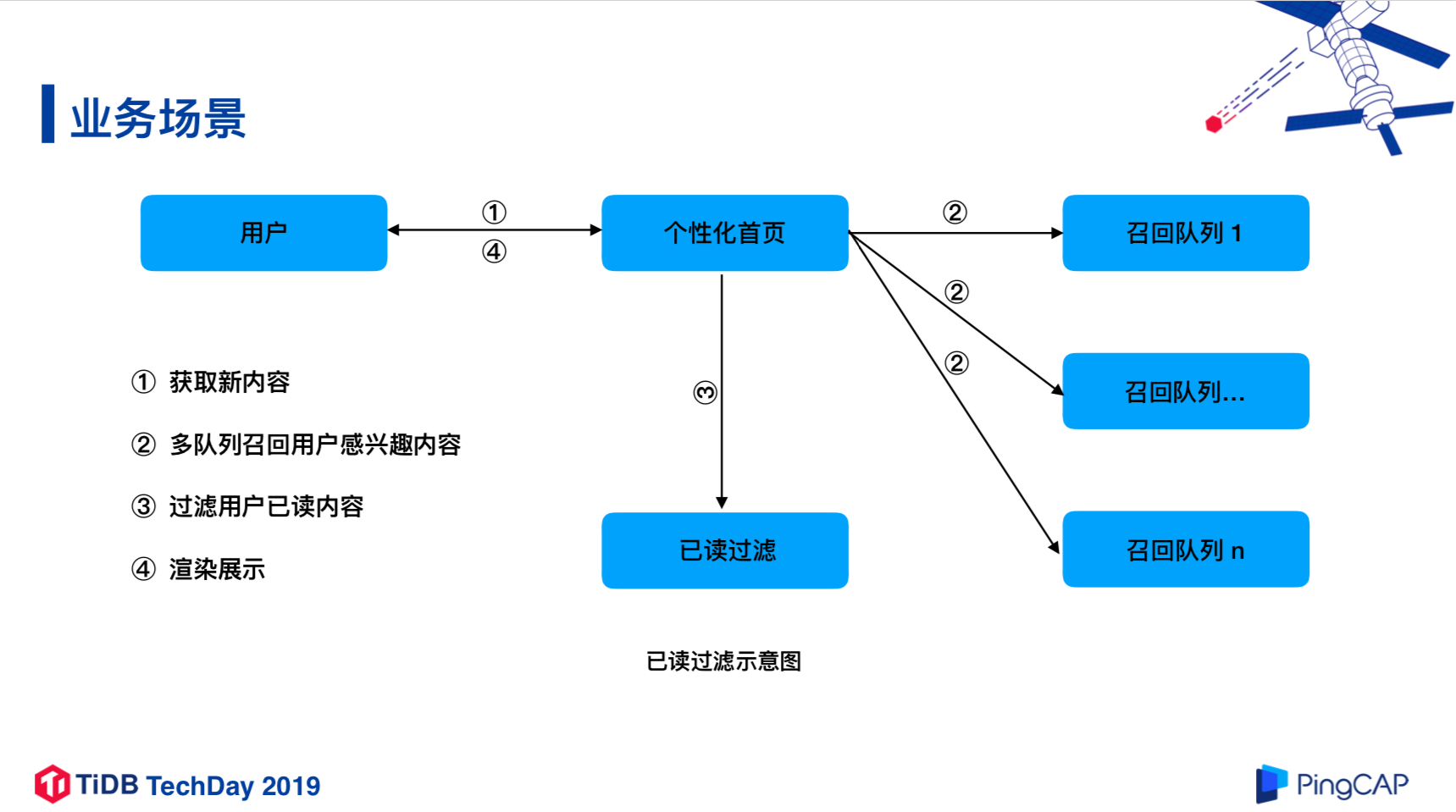
业务特点
可用性要求高
个性化首页推送,是最重要的流量分发渠道
写入量大
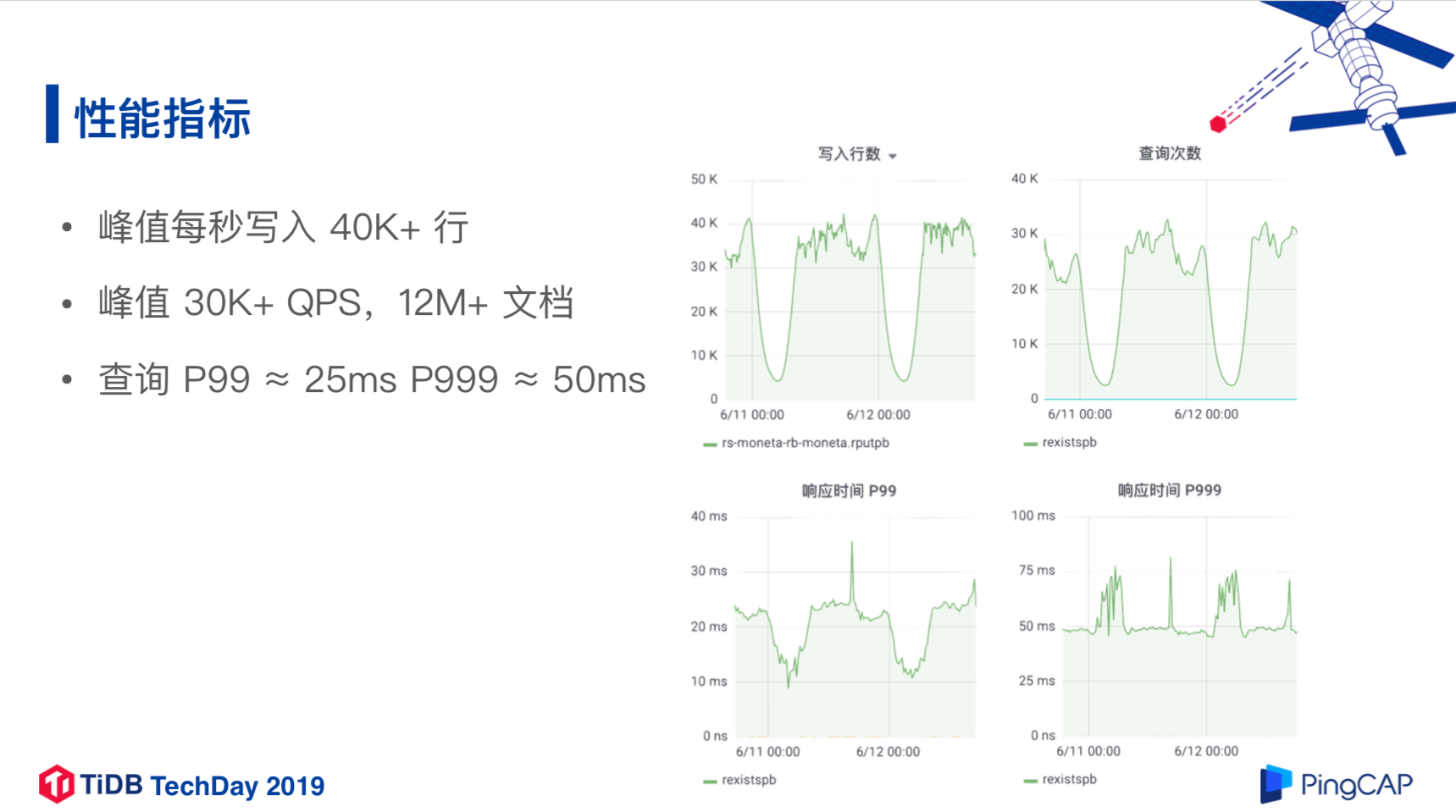
峰值每秒写入40K+行记录,日新增记录金30亿条
历史数据“长期”保存
已读历史记录保存三年,近一万三千亿条数据
查询吞吐高
峰值30K+QPS,每秒大概产生 3 万次独立的已读查询
响应时间敏感
整个查询响应时间(端到端超时)是 90ms
可以容忍“false positive”(误报)
已读服务架构
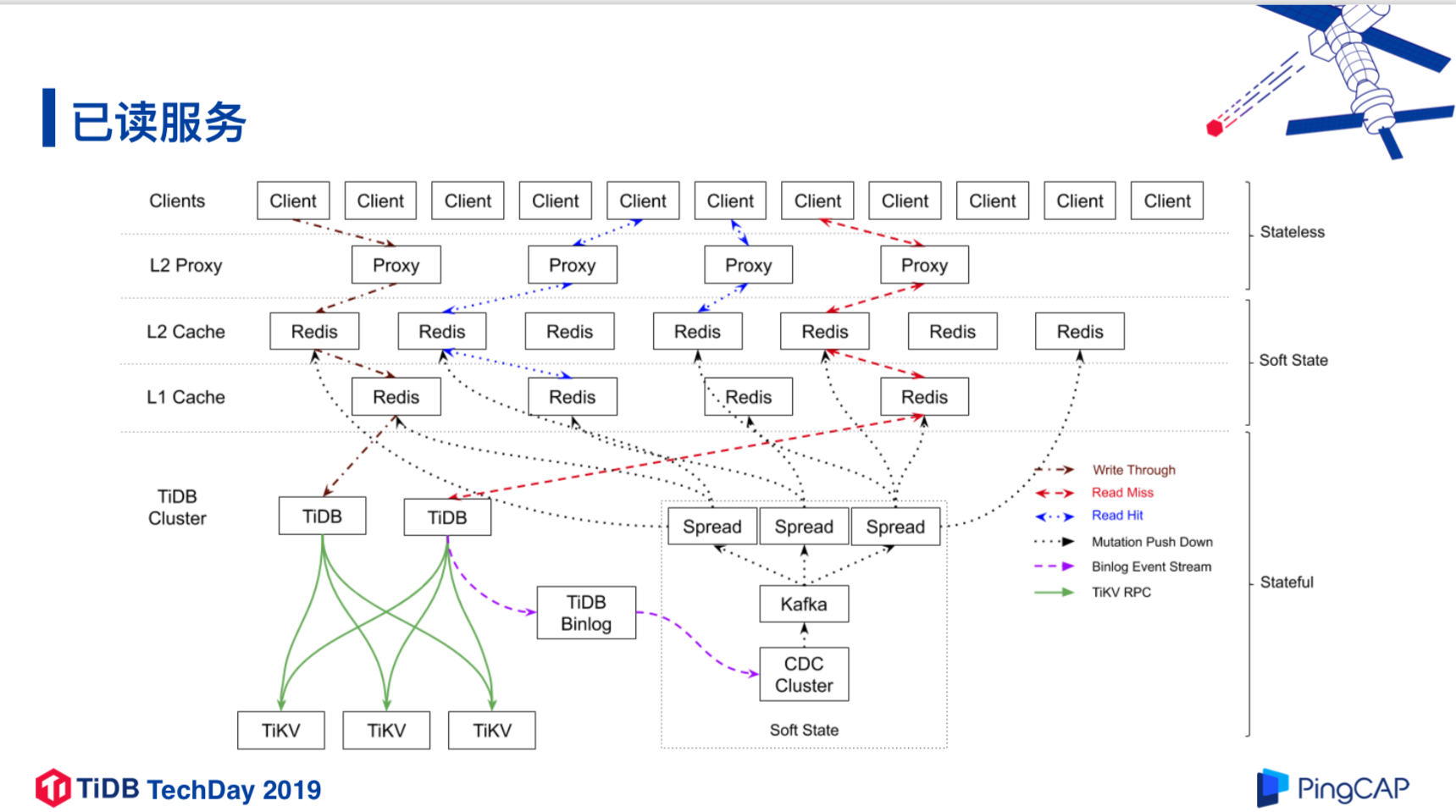
为什么选用TiDB
分库分表 + MHA(Master High Availability) 机制 在流量不大时可以忍受,但在每月新增一千亿数据的情况下,需要思考的就是怎样让系统可持续发展、可维护。
TiDB 兼容 MySQL,完全支持 ACID 事务,可扩展性好。
性能指标
TiDB 3.0 GA
性能和稳定性提升
TiDB 3.0 版本显著提升了大规模集群的稳定性,集群支持 150+ 存储节点,300+TB 存储容量长期稳定运行。易用性方面引入大量降低用户运维成本的优化,包括引入 Information_Schema 中的多个实用系统视图、EXPLAIN ANALYZE、SQL Trace 等。在性能方面,特别是 OLTP 性能方面,3.0 比 2.1 也有大幅提升,其中 TPC-C 性能提升约 4.5 倍,Sysbench 性能提升约 1.5 倍,OLAP 方面,TPC-H 50G Q15 因实现 View 可以执行,至此 TPC-H 22 个 Query 均可正常运行。新功能方面增加了窗口函数、视图(实验特性)、分区表、插件系统、悲观锁(实验特性)。
Windows Terminal安装教程及操作
安装
Microsoft Store 找 Windows Terminal 安装预览版
Microsoft Store 搜索 Linux 可以安装 内置 Linux ,PC 用的比较多的就是 Ubuntu 和 Debian 了。目前我使用的是 Debian ,当然也有 CentOS 。
不过这都不重要,最重要的是 wsl 和 windows 共享网络栈和文件系统